Compounder
A value-investing research engine: a deterministic 100-point scorer for the numbers, plus a 12-step LangGraph agent that reads the filings and writes the analysis.
Compounder is a local-first research engine for value investing. It pulls a company's filings, prices, insider activity, and macro backdrop into one place, scores the business against a fixed 100-point rubric, then runs a multi-step agent that reads the filings and writes the kind of qualitative analysis a human would.
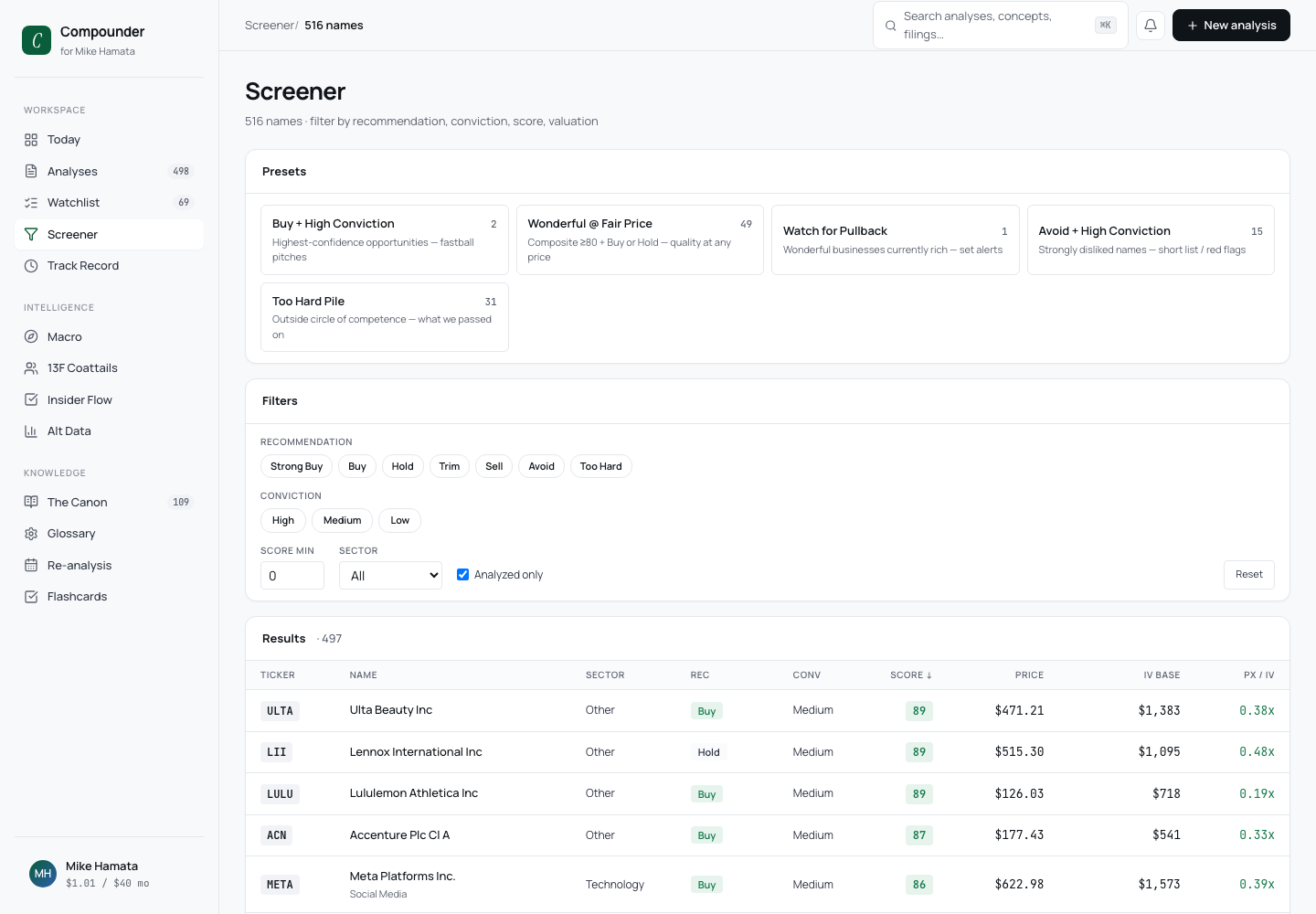
The problem
Fundamental research has a consistency problem. The same analyst, reading the same 10-K on two different days, weights it differently, and across a watchlist of dozens of names the judgment drifts. Compounder's bet is that the scoring should be mechanical and identical every time, and the judgment should be the one place a model earns its keep, never the other way around.
The line between deterministic and probabilistic
The whole thing hangs on one decision: what is allowed to be probabilistic, and what is not.
- The 100-point score is pure arithmetic. Four categories worth twenty-five points each (profitability, balance sheet, capital allocation, valuation), five sub-metrics apiece, all computed in plain Python from the financial data. No model touches it. Run it twice on the same filing and you get the same number to the point. A score you can't reproduce is a score you can't trust.
- The narrative is the agent's job. Once the number is fixed, a twelve-step pipeline reads the filings and writes the analysis: the moat argument, the management read, the industry dynamics, an inversion (what would have to go wrong), and a synthesis with position guidance. The model interprets; it never gets a vote on the score.
It's the same line a risk desk draws by reflex: keep the number auditable, and let judgment sit on top of the number rather than inside it. When something looks off, you can point at the exact step that produced it.
The pipeline is a graph, not a prompt
The twelve steps are an explicit LangGraph state graph, not one giant prompt doing everything at once. Each node has a defined input and output, so a failure is localized to a step instead of smeared across a single call, and the graph is allowed to branch. The fourth node is a Circle of Competence gate, straight out of Munger: if the business is outside what the system can actually evaluate, the run routes to "too hard" and stops rather than manufacturing confidence about something it doesn't understand. Saying "I don't know" is a feature here, not a failure.
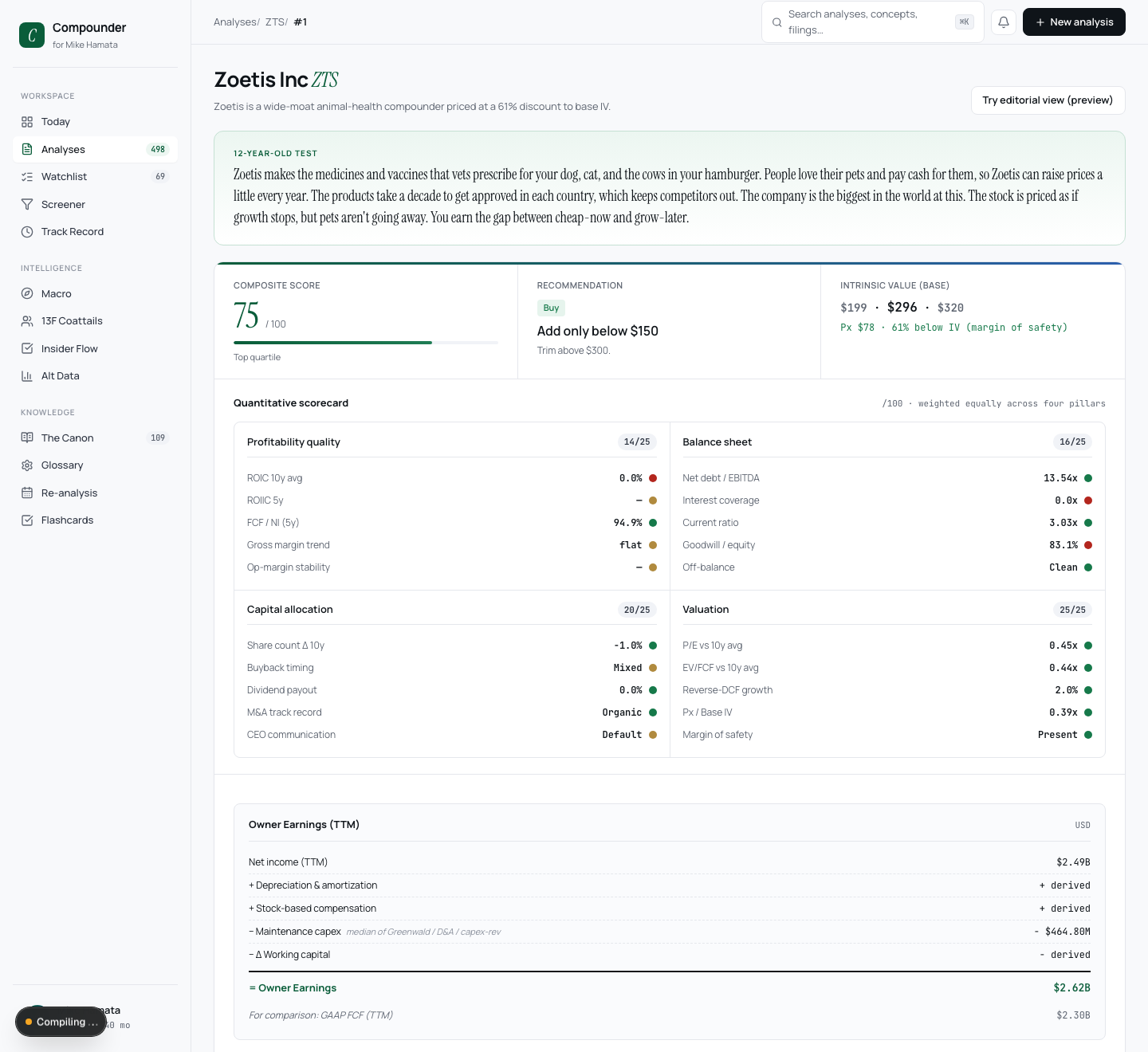
The work is split across model tiers by how hard each step is: a cheap model handles the gate and the simple classification, a mid model does the bulk of the analysis, and the strongest one is held back for the inversion and the final synthesis. It all runs behind hard cost caps, a few dollars per analysis and a fixed monthly ceiling, because an agent that reads filings on a schedule is a cost surface, and an uncapped one is a bad night waiting to happen.
Grounded in the right canon
Each analysis step retrieves from an embedded corpus of the actual source material, Buffett's shareholder letters, Munger's talks, Damodaran's valuation work, so the writing is anchored to that canon instead of the model's fuzzy memory of it. Retrieval is hybrid: vector similarity, keyword match, and metadata filters combined, so a query lands on the right passage whether you remember the exact words or just the idea.
How it runs
Compounder isn't a chatbot you poke at, it's a system that wakes up on its own. A daily job pulls fresh prices and macro data, checks EDGAR for new filings, and tracks Form 4 insider activity, surfacing anything material for another look. A weekly job compiles a long-form Sunday edition. The web UI is where you read the output: a screener ranked by score, the full analysis per company, the macro tape, and the 13F "coattails" of investors worth following.
What broke
The last step of the pipeline writes the verdict: recommendation, conviction, buy and trim prices. The first version had the model write those in Markdown and pulled them out with regex. It worked until it did not. Bold markers around a heading, a comma in a price, a parenthetical aside, and the regex would miss, and the code would quietly fall back to defaults: Hold, medium, no price. Nothing crashed. The analysis read beautifully. The recorded verdict under it was wrong, and the only way to know was to read both and compare.
That is the failure mode I wrote a whole essay about, happening in my own system: functioning beautifully in the direction of the wrong answer. The fix was to stop parsing prose. The model now submits the verdict through a tool call with a strict schema, where the recommendation is an enum and the prices are numbers or null, and there is no parsing layer to drift. If it cannot fill the form, that fails loudly at the API. A model should fill in forms, not write documents you then guess at with patterns.
Related writing: Book notes: the RAG chapter of AI Engineering, on why the hybrid retrieval here works, and What a risk desk taught me about evaluating AI agents.